
Federated Learning
Federated Learning (FL) is a decentralized approach to machine learning that enables multiple devices or institutions to collaboratively train models without sharing raw data. Unlike traditional centralized learning, where data is aggregated in a single location, FL keeps data localized while only exchanging model updates. This framework is particularly valuable in privacy-sensitive applications such as healthcare, finance, and mobile devices, where data security and regulatory compliance are paramount. FL can be implemented in various architectures, including horizontal FL (where clients share the same feature space) and vertical FL (where different institutions contribute complementary data features).
The benefits of FL are substantial. By keeping data decentralized, FL enhances privacy and security while reducing the risk of data breaches. It also enables learning from diverse data sources, improving model generalization across different environments. Furthermore, FL reduces communication overhead by transmitting only model updates rather than large datasets, making it well-suited for edge devices with limited bandwidth. This approach also allows for personalized model training, where each client can fine-tune models based on local data while still benefiting from collective knowledge.
Despite its advantages, FL faces several challenges:
- Communication efficiency: Frequent model updates across multiple clients can introduce latency and synchronization difficulties.
- Data heterogeneity: Different clients may have varying data distributions, leading to imbalanced learning and reduced model fairness.
- Security risks: FL is susceptible to adversarial attacks and model poisoning, which can compromise training integrity.
- Model size constraints: A growing challenge is the increasing size of deep learning models, particularly large language models (LLMs), which often require the entire model to reside on the client. This imposes significant computational and memory constraints, making it difficult for resource-limited edge devices to participate.
Our research aims on addressing some of these limitations, by carefully applying methods such as compression, pruning, as well as designing adaptive aggregation strategies.
Selected Publications
-
Jiang, Y., Wang, S., Valls, V., Ko, B. J., Lee, W. H., Leung, K. K., & Tassiulas, L. (2022). Model pruning enables efficient federated learning on edge devices. IEEE Transactions on Neural Networks and Learning Systems, 34(12), 10374-10386.
-
Luo, B., Li, X., Wang, S., Huang, J., & Tassiulas, L. (2021, May). Cost-effective federated learning design. In IEEE INFOCOM 2021-IEEE Conference on Computer Communications (pp. 1-10). IEEE.
-
Luo, B., Xiao, W., Wang, S., Huang, J., & Tassiulas, L. (2022, May). Tackling system and statistical heterogeneity for federated learning with adaptive client sampling. In IEEE INFOCOM 2022-IEEE conference on computer communications (pp. 1739-1748). IEEE.
Split Learning
Split Learning (SL) is a distributed machine learning paradigm where a model is split between clients and a central server, reducing the computational and memory burden on edge devices. Instead of training a full model locally, clients process only the first few layers and send intermediate activations to the server, which completes the forward and backward passes. The gradients are then sent back to the clients for updating the local portion of the model. This approach is particularly useful in scenarios where clients have limited computational resources but still require privacy-preserving learning.
SL offers several advantages over Federated Learning (FL). By offloading a significant portion of computation to the server, SL allows low-power devices to participate in training without storing or processing large models. Additionally, since raw data never leaves the client, SL maintains data privacy, similar to FL. However, unlike FL, where full model updates are transmitted, SL only exchanges activations and gradients, potentially reducing communication overhead while also enhancing model training efficiency on constrained devices.
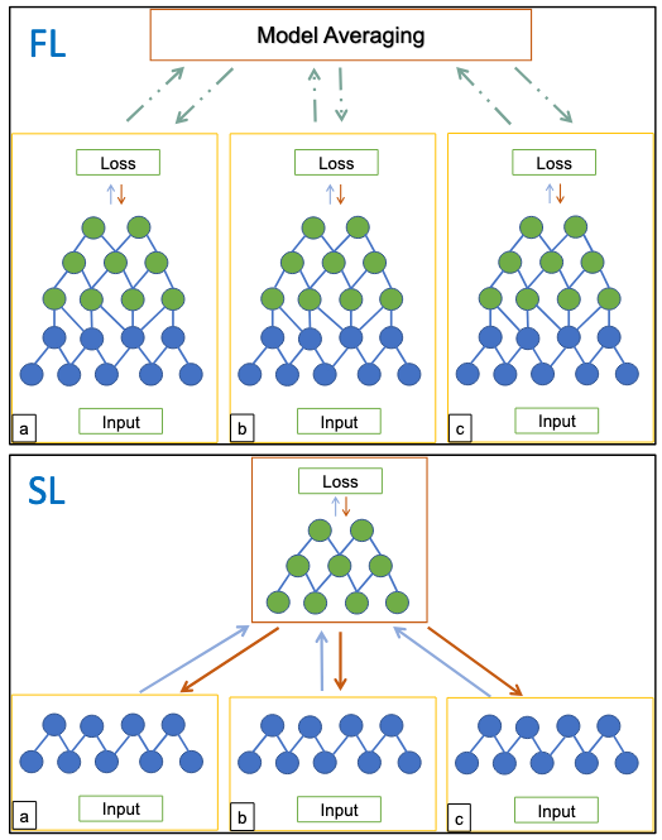
While SL mitigates some challenges of FL, it introduces new trade-offs and limitations:
- Communication overhead: SL requires frequent activation and gradient exchanges, which may introduce latency issues, particularly with large models or slow networks.
- Privacy risks: Although raw data remains local, activations can still leak sensitive information, necessitating privacy-preserving techniques such as differential privacy and homomorphic encryption.
- Server dependency: Unlike FL, which enables fully decentralized learning, SL relies on a centralized server, making it a single point of failure and a computational bottleneck under heavy workloads.
- Limited support for asynchronous learning: SL typically requires synchronous updates, meaning clients and the server must stay connected and exchange information in real time, limiting its applicability in heterogeneous and unreliable networks.
- Scalability constraints: While SL reduces client-side computation, handling a large number of clients increases server-side workload, potentially negating efficiency gains in large-scale deployments.
Comparison with Federated Learning
Both Split Learning and Federated Learning have distinct advantages and challenges. FL enables fully decentralized learning but struggles with large models on clients, whereas SL reduces client-side burden but depends on server coordination and frequent communication. Choosing between them depends on the application’s constraints on computation, privacy, scalability, and network reliability.
Our research on Split Learning focuses on adaptive compression mechanisms that account for dynamic network conditions, without sacrificing performance.
Selected Publications
-
Mudvari, A., Vainio, A., Ofeidis, I., Tarkoma, S., & Tassiulas, L. (2024). Adaptive compression-aware split learning and inference for enhanced network efficiency. ACM Transactions on Internet Technology, 24(4), 1-26.
-
Mudvari, A., Jiang, Y., & Tassiulas, L. (2024). Splitllm: Collaborative inference of llms for model placement and throughput optimization. arXiv preprint arXiv:2410.10759.